Project: DAVAI
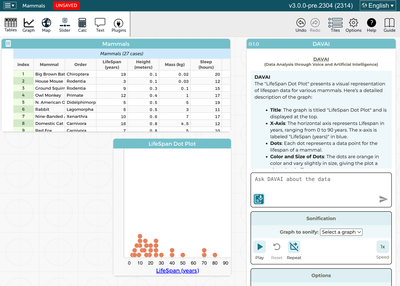
CODAP screenshot showing the DAVAI plugin

DAVAI (Data Analysis through Voice and Artificial Intelligence) is an exploration of using AI large-language models to allow students—especially those who are blind or low-vision—to work with data in the Concord Consortium's data-analysis environment CODAP.
CODAP is a free Concord Consortium tool that allows students to explore datasets and learn about data science by creating graphs, organizing and re-arranging the data properties, and annotating and sharing the results. It also support a rich plugin ecosystem that allows it to be adapted for related uses. However, it was not developed multiple modalities in mind; using CODAP requires the ability to see and organize windows on the display, and to make extensive, precise use of drag and drop.
The Data By Voice project is a partnership between Concord Consortium and Perkins Access Consulting, working closely with accessibility experts and BLV students to design, prototype, and test technologies that can allow students to make plain-English requests, by typing or speaking, to actively explore data—asking for particular representations of a large, multi-faceted dataset to be created, described, or sonified. DAVAI is the product of this work.
Requests such as the following can be typed or spoken by the user, with screen-reader-friendly or self-voiced responses from the system:
- Make a graph of height versus weight for the 'mammals' dataset
- Switch the X and Y axes
- Describe the shape of the graph for weights between 100 and 500 kilograms
- Sonify the graph (which results in a series of tones being played based on the values of the points)
My role: I participated in the project as a software engineer and did deep dives into AI technologies such as RAG, structured outputs, code generation, and orchestration tools.
Technologies: Large-langauge models (ChatGPT, Gemini), Langchain, RAG, Typescript, CODAP APIs.
Description: Implementing DAVAI required using the LLM API as a bridge between users' requests and the CODAP API calls that could accomplish them. CODAP APIs are presented to the LLM as a set of available tool calls. DAVAI itself is the middleman, sending user input to the LLM, forwarding tool requests to CODAP and their results back to the LLM, and eventually displaying the response to the user.
Certain requests involved additional processing, such as generating an image of a graph to pass to the LLM when a description of it was requested by the user.